TEDの英語原稿を取得する
方針
http://www.ted.com/talks/subtitles/id/# {固有のID}/lang/en を叩くと、英語原稿のjsonが返ってくる。
TEDのビデオの固有のIDを取得して、API叩いて、jsonをparseして、出力すればいけそう。
jsonのパース
gem install jsonrequire 'rubygems'
require 'open-uri'
require 'json'
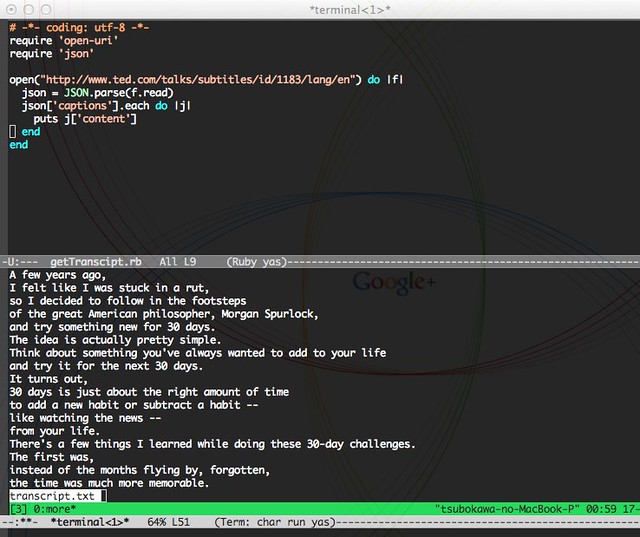
open("http://www.ted.com/talks/subtitles/id/1183/lang/en") do |f|
json = JSON.parse(f.read)
json['captions'].each do |j|
puts j['content']
end
endこんな感じで取得できそう。
固有IDを取得するために、nokogiriでHTMLをparseする
brew update
brew install libxml2 libxslt
gem install nokogirirequire 'rubygems'
require 'open-uri'
require 'json'
require 'nokogiri'
url = "http://www.ted.com/talks/brene_brown_listening_to_shame.html"
doc = Nokogiri::HTML(open(url))
ted_id = doc.xpath("//div[@id='share_and_save']").first.attribute("data-id")
open("http://www.ted.com/talks/subtitles/id/#{ted_id}/lang/en") do |f|
json = JSON.parse(f.read)
json['captions'].each do |j|
puts j['content']
end
endスクレイピングの方法がわからなくて四苦八苦。以下を参照して、怪しげながら、固有IDの取得。
できた
参考
Backlinks
TED APIを触ってみる
TED - Welcome to TEDLabs いつのまにかTEDのAPIが公開されていたので、少し触ってみる。
2017/09/01追記 TED APIのサービスは終了となりました。
昔は、APIが公開されてなかったので、スクレイピングで取得していた。 (htmlの構造が今は変わってるので、以下のコードでは取得できません)
2014-11-21
小さい成長。
小さい成長を。一歩ずつ。step by step。
どうも、3年目になってしまった@meganiiです。 「ちょっとは成長したのかなぁ?」ってつぶやいたら、@nijinochichiさんに「無理矢理にでも成長ポイントを探すべし!」とコメントいただいたので、探してみました。
小さい成長点 Programming Network Blog Programming ようやくプログラミングを使えるなってきた。
今までは、各フレームワーク(Railsなど)のチュートリアルをひと通り触っただけで、終わっていたし満足していた。
2012-03-31
TEDから取得したmp3に英語原稿を埋め込む
TEDの英語原稿を取得するで取得した英語原稿をダウンロードしたmp3ファイルに埋め込みたい。
調べてみると、id3lib-rubyが使えそう。
id3lib-rubyを利用してmp3に歌詞情報を埋め込む id3lib-ruby - ID3 tag library for Ruby mp3のタグを扱うライブラリid3libのラッパー 準備 brew install id3lib gem install id3lib-ruby
Lyricsに英語原稿を設定 require 'rubygems' require 'id3lib' # TEDからダウンロードしたmp3ファイルの読み込み tag = ID3Lib::Tag.new('ted.mp3') # 英語原稿を歌詞情報として登録 tag.lyrics = "TEDから取得した英語原稿" # 更新 tag.update!
できた!
2012-03-21